Introduction
This project involved building and benchmarking a scalable three-tier lakehouse solution on Google Cloud Platform (GCP) as part of a comprehensive Terraform IaC DevOps Course. The course focused on leveraging Infrastructure as Code (IaC) principles, implementing CI/CD pipelines, and utilizing various GCP services for big data processing and analysis.
Goals
- Infrastructure as Code (IaC): Provision computing resources for big data analysis using Terraform.
- CI/CD Pipelines: Set up automated pipelines for deploying cloud infrastructure using GitHub Actions.
- Security: Utilize linters to detect security vulnerabilities in the infrastructure and implement Workload Identity Federation for secure authentication between GitHub Actions and GCP.
- Big Data Processing: Run Apache Spark code in a distributed manner on a Hadoop cluster using Vertex AI notebooks and Dataproc.
- Benchmarking and Scalability: Perform benchmarking and scalability tests of the lakehouse solution using the TPC-DI benchmark, dbt, GCP Composer (managed Apache Airflow), and Dataproc.
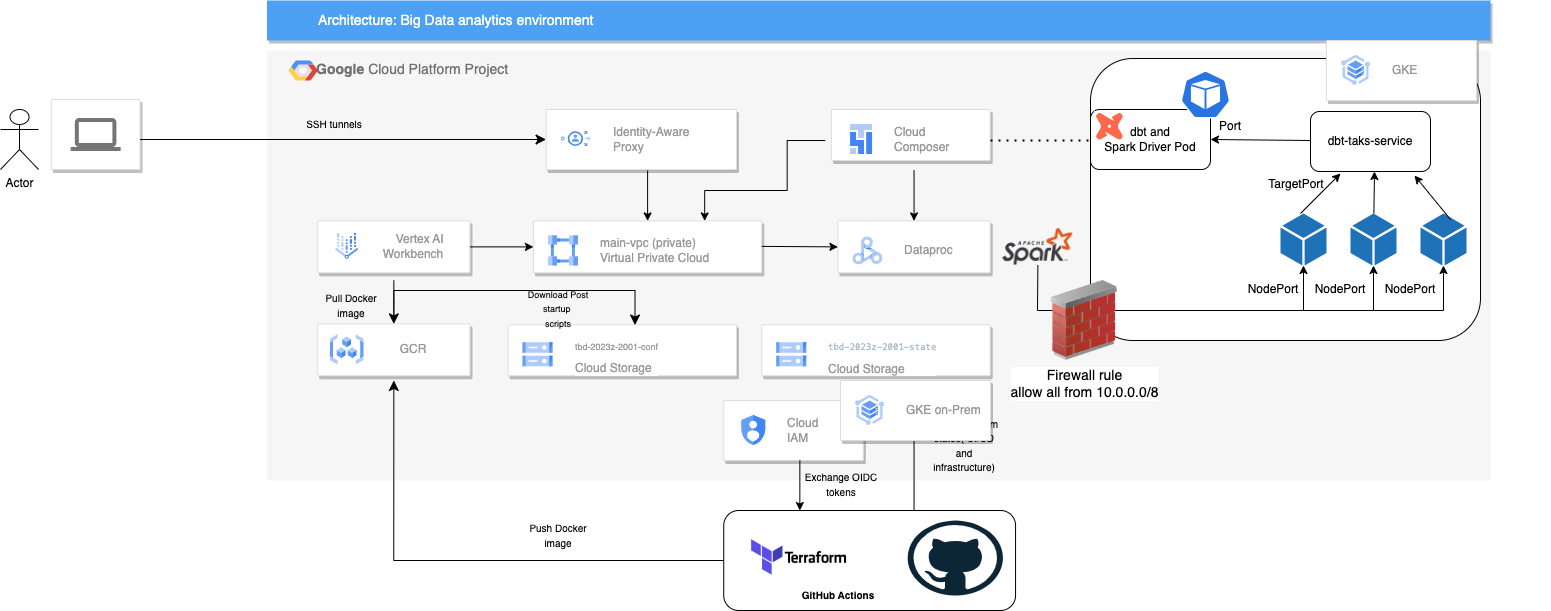
Architecture
The project implemented a three-tier lakehouse architecture on GCP, utilizing services such as:
- Vertex AI Workbench: Managed JupyterLab environment for interactive data analysis and development.
- Dataproc: Managed Apache Spark and Hadoop service for distributed data processing.
- Composer: Managed Apache Airflow service for orchestrating data pipelines.
- Cloud Storage: Storing data for the lakehouse.
Phases
Phase 1: Infrastructure Setup and CI/CD
This phase focused on setting up the GCP project, provisioning infrastructure using Terraform, and configuring CI/CD pipelines with GitHub Actions and Workload Identity Federation.
Phase 2a: Data Loading and Transformation
This phase involved:
- Using a provided Jupyter notebook to generate and load data into the lakehouse.
- Exploring the generated data files and understanding their format, content, and size.
- Analyzing the data loading process using SparkSQL.
- Implementing data transformations using dbt and running them through the orchestrated data pipeline.
- Adding custom dbt tests to ensure data quality.
Phase 2b: Benchmarking and Scalability Testing
This phase focused on:
- Modifying the Dataproc cluster configuration to test different machine types.
- Running dbt with varying numbers of Spark executors (1, 2, and 5).
- Collecting and analyzing the performance data, including total execution time and individual model execution times.
- Visualizing and discussing the scalability of the solution based on the collected data.
Technologies Used
- Google Cloud Platform (GCP): Vertex AI, Dataproc, Composer, Cloud Storage, IAM
- Terraform: Infrastructure as Code
- GitHub Actions: CI/CD
- Workload Identity Federation: Secure Authentication
- Apache Spark: Distributed Data Processing
- Hadoop: Distributed File System and Resource Management
- dbt: Data Build Tool
- TPC-DI: Benchmark for Data Integration
- Apache Airflow: Workflow Management Platform
- JupyterLab: Interactive Development Environment
- Python: Programming Language